Free SEO Tools
SEO Check
Google Bot can render your website with or without JavaScript. Better be ready.
Questions Tool
Find all questions users have asked Google.
Check Local Rankings
Get local rankings for over 90.000 places.
Ultrasuggest / Keyword Tools
Create hundrets of related keywords based on the suggests of Google, Amazon, YouTube, Ebay, Wikipedia ..
SEO Spider / Crawler
Without a good SEO crawler there is no technical SEO.
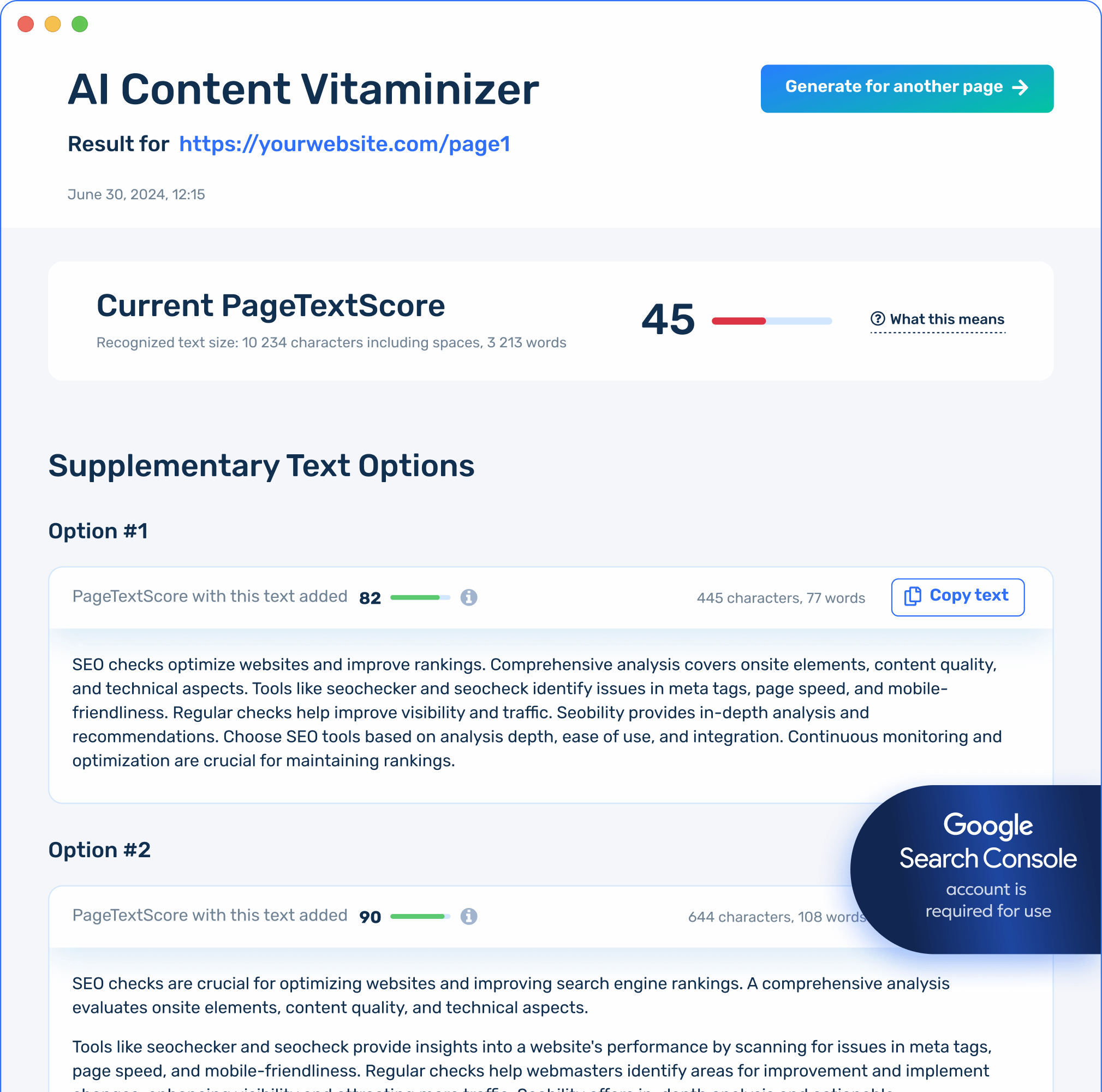
TRY OUR NEW FEATURE
FREE Content Vitaminizer: AI SEO Texts That Work
Generate a powerful supplement for your page: a compact content piece relevant to hundreds of search queries and apt to make the page more helpful for users